Go to Optimise > Cluster 1 Analysis (capacity)
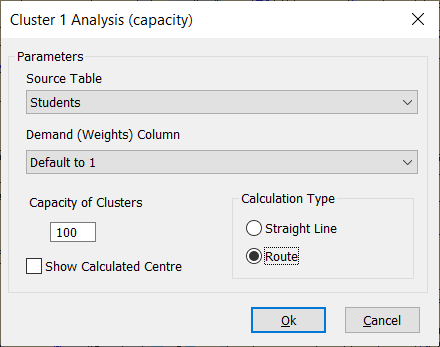
This function solves the problem of clustering customers into clusters with a given capacity, so total distance between cluster center and customers is minimized, while capacity is respected. An optional weight can be also be taken into account. It is aimed at sorting different objects into meaningful groups.
Parameters
You first need to pick the point table you want to use.
You can select a column that represents the demand for each point. For instance a point might represent a different number of survey points.
If a specific column is not selected then each point will have a default demand of 1.
Next you have to input the capacity of the clusters you would like the function to produce. You can also select the option to show the centre point of each group just tick the box.
The higher the capacity, the less clusters are produced.
Calculation type
The cluster algorithm uses a matrix in order to work. This can be a straight line or a calculated route distance. The straight line is very quick but is not as accurate as a routed distance, There is an example below.
Click OK to perform the calculation.
If you have selected the route matrix type then you might see the following progressbar.
If your table does not have a column to store the result then you will see this prompt:
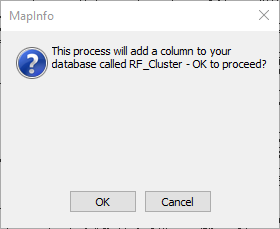
If you click "Yes" then the column is added as in integer column. The result of the clustering is stored in this column in the original table.
You will get a message if that tables you select have deleted rows or have records that are not geocoded.
Otherwise the calculated groups will be displayed.
Performance
If you are using a uniform demand of 1, then a more advanced method is used, which gives very good results, but is slower than with non-uniform demand. For instance if you use the sample data and the 1000 students, grouped into clusters with a capacity of 100, it takes ~ 15 minutes to get a result.